JS面经
JS 面经
JS 由哪三部分组成
js 由 ECMAScript,DOM(文件对象),BOM(浏览器对象)组成
ECMAScript 就是 js 的核心语法,比如说变量,函数,数据类型,if,while 操作语句等等
然后 DOM 就是操作文档的对象,这个对象是封装好的,比如说 document 对象,可以操作文档的一些属性,比如说文档的标题,文档的内容等等
然后 BOM 就是 window 对象,这个对象是浏览器提供的,比如说,alert,confirm,prompt,location,history
js 有哪些内置对象
JS 的内置对象有很多,比如说 Math,Date,String,Object,Number
在这里讲几个比较常用对象的常用方法
Math
let math = Math;
console.log(
math.sqrt(4),
math.abs(-1),
math.ceil(1.1), // 向上取整 2
math.floor(1.5), // 向下取整 1
math.round(1.6), // 最近取整 2
Math.trunc(1.6), // 去掉小数部分 1
math.max([1, 2, 3]), // NAN 因为Max不能传入数组,只能在一组数字参数中比较最大值 Max(1,2,3)
math.min(1,2),// 1
math.random() // 0-1 之间的随机数 如果要生成别的范围的随机数的话就是 math.random() * (max - min) + min
Number
let num = 1;
console.log(
num.toString(), // 1
num.toFixed(2), // 1.00
num.toExponential(2) // 1.00e+0
);
num = 21.22222222;
console.log(
num.toFixed(2), // 保留小数点后几位
num.toPrecision(5) // 保留几位有效数字算上整数位
);
String
let str = "hello";
console.log(
str.charAt(0), // h 返回指定位置的字符
parseInt(str), // NAN 数字开头的字符串解析
parseInt("123"), // 123
str.slice(1, 3), // el
str.padStart(1, "a") // 在字符串前面填充字符
);
操作数组的方法
判断数据类型的方法
基本数据类型和引用数据类型
再提一嘴 JS 的
原始数据类型(基本数据类型),
String,Number,Boolean,Null,Undefined,Symbol,BigInt在地址中就是值本身
引用数据类型就是复杂的数据类型,比如说 Object,Array,Function
然后引用数据类型是存储在堆内存中的,然后如果两个引用数据类型指向了同一个地址,那么你修改一个的时候,另一个也会被修改
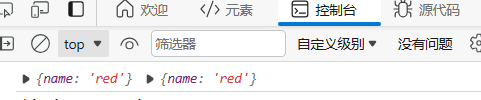
// 引用数据类型
let testObj = {
name: "blue",
};
let testObj1 = testObj;
testObj1.name = "red";
console.log(testObj, testObj1);
什么是闭包
闭包其实简单来说就是一个作用域,函数套函数,内部的函数可以调用外部函数的参数
简单示例
function test() {
let a = 1;
return function () {
console.log(a);
a++;
};
}
let result = test();
result(); // 1
result(); // 2
闭包的用途
- 像类一样封闭私有变量,让外部可以调用内部的变量,私有模块
function testModule() {
let pri = 1;
let pub = 2;
function getPub() {
return pub;
}
return {
getPub,
};
}
let result = testModule();
let pub = result().getPub(); // 2 可以拿到值
let pri = result().pri; // 不能直接拿到值
- 做到一个缓存的作用,因为闭包是不会被垃圾回收机制回收的
function store() {
let state = {};
return function (key, value) {
if (value) {
state.key = value; // 如果有设置值的话就设置值
} else {
return state.key; // 如果再次调用的话就直接返回
}
};
}
let store1 = store();
store1("a", 1);
console.log(store1("a"));
console.log(store1("a")); // 赋值了第二次直接就拿缓存的数据了
store1("a", 2);
console.log(store1("a"));
- 用于循环中的异步操作
for (var i = 0; i < 5; i++) {
setTimeout(() => {
console.log(i);
}, 1000);
}
- 用于防抖,节流
ES6
什么是 apply,call,bind,他们的区别是什么
apply,call,bind 方法都是改变上下文的,即改变 this 的,他们都是作用于一个函数上
apply(this,[arg1,arg2])
call(this,arg1,arg2)
let bindFn = fn.bind(this,arg1,arg2)
看上面三个例子就能看出这三者的区别,apply 和 call 是立刻执行,他们的唯一区别就是 apply 如果是传入参数的话传入的是数组,而 call 是参数列表仅此而已
bind 就是延迟使用
用一个充电宝的例子来解释,John 的手机有 90 电,他调用函数充了 10 的电,然后这个时候 mike 想要电宝,就叫 john 借给他,这个时候电宝的主人就变成了 mike,然后 mike 用完了
而 bind 呢,就是这个时候,john 先把电宝借给了 Amy,然后 amy 再给 mike 充电
// 拿充电宝的例子来解释
const mike = {
name: "mike",
battery: 50,
charge: function (battery) {
this.battery += battery;
},
};
const john = {
name: "john",
battery: 90,
charge: function (battery, battery1) {
this.battery += battery + battery1;
},
};
console.log("john", john.battery); //90
john.charge(10, 20); // 120
console.log("john电", john.battery); // 120
console.log("mike", mike.battery); // 50
// john.charge.apply(mike, [10, 20])
// john.charge.call(mike, 10, 20)
// bind 就是延迟使用 永久改变this指向,返回一个函数
const newBattery = john.charge.bind(mike);
newBattery(10, 20);
console.log("mike电", mike.battery); // 80
- apply 的另一个用途就是,他可以很简单的实现找数组的最大值
关于参数传 null 的原因其实就是传入默认对象
let arr = [1, 2, 3, 4, 5];
let maxx = Math.max.apply(null, arr);
讲一下防抖,节流,怎么实现
JS 的垃圾回收机制
在 js 中定义的函数及其参数,全局变量,调用链上的函数等都是不会被垃圾回收机制回收的
js 中的垃圾回收机制本质就是可达性
比如说我有一个对象,我可以访问到,就是把 this 指向他,表示这货是可达的,那么这个对象就不会被垃圾回收机制回收
然后 js 是垃圾回收算法本质就是
标记和清除
从根开始标记所有可达的对象,然后清除所有没有标记的对象
FROM gpt
标记(Marking):垃圾回收器会从一个称为"根"的起始点开始,标记所有可以访问到的对象。根可以是全局对象、当前执行上下文中的变量和参数,以及调用栈中的对象引用。通过从根出发,垃圾回收器遍历对象之间的引用关系,并标记所有可达的对象。
清除(Sweeping):在标记阶段之后,垃圾回收器会扫描内存中的所有对象,并清除没有被标记的对象。这些没有被标记的对象被认为是不再被使用的,它们所占用的内存将被释放。
js 的内存泄露
像计时器,闭包太多,直接为声明赋值,反复引用都会导致内存泄露
// 导致内存泄露的原因
// 1. 闭包太多
// 2.无效引用
function test() {
let obj = {};
return obj;
}
let result = test(); // obj不会被垃圾回收机制回收
// 3. 定时器
function statTimer() {
let timer = setInterval(() => {
console.log("timer");
}, 1000);
return timer;
}
// let timer = statTimer() // 需要手动清除定时器 clearInterval(timer)-+-
//4. 为声明直接赋值的变量
let a = 1; // window.a = 1 这样就是直接为window对象添加了一个属性,这样就不会被垃圾回收机制回收
// 5 . 反复引用
let obj1 = {};
let obj2 = {};
obj1.name = obj2;
obj2.name = obj1;
// 这样就会导致内存泄露,因为obj1和obj2都引用了对方,所以就不会被垃圾回收机制回收
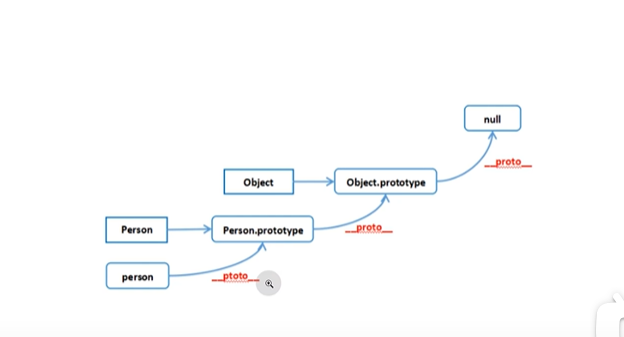
JS 的原型链
ES6 模块和 cjs 的区别
先说结论
- es6 模块是编译时引入,commonjs 是运行时引入
- es6 模块是只读的,而 cjs 模块是浅拷贝
- 这俩用法就不同,然后现在推荐使用 es6 模块
es6 模块长什么样,怎么定义使用,特性是什么
19 年后(node16)就推行使用 es6 模块了,es6 模块内部是私有的,想要使用的话只能使用 export 导出
其实就是我们非常熟悉的 import export
定义模块
const count = 1
export default count
or
export const count
// 使用
import count from './count'
or
import {count} from './count'
他有几个特性
- es6 模块是静态的,也就是说他是在编译的时候就确定
- es6 模块的异步加载的,所以我们也会经常在使用某些方法时,使用
await import()来加载模块 - es6 模块的 read-only 的,不能修改导入的模块
- es 模块会在 package.json 中的 type 字段中指定,如果是 module 的话就是 es 模块,如果是 commonjs 的话就是 cjs 模块
cjs 模块长啥样,怎么定义,使用,特性是什么
cjs 模块就是在有 es 模块之前,使用的最广泛的模块化
使用
const count = 1;
const add = (a, b) => a + b;
module.exports = count;
module.exports = {
count,
add,
};
// 使用
const count = require("./count");
cjs 模块是同步的,动态的,只有在实际运行时才会引入
因为这些模块相当于是下载到了本地,require 方法是同步的
然后 cjs 只能 node 服务器环境下才能使用
为什么 nodeModules 里的模块都是 cjs 模块
一个是历史遗留问题,因为早期的时候 node 是没有 es6 模块的,所以只能使用 cjs 模块
然后是考虑到兼容性的问题,因为我们使用 nodemodules 的时候,都会先 install,只是引入的时候几乎都是需要使用 import 的了,老的包可能还只能使用 require
什么是 AMD,CMD
AMD 表示异步模块定义,CMD 表示通用模块定义,他们都是为了解决模块化的问题
AMD(Asynchronous Module Definition)
AMD 是由 RequireJS 提出的一种模块定义规范,它支持异步加载模块,允许模块在加载完成后立即使用。AMD 规范要求模块必须使用 define 函数来定义,使用 require 函数来加载依赖模块。
// 定义模块
define(["dependency1", "dependency2"], function (dep1, dep2) {
// 模块代码
});
// 加载模块
require(["module1", "module2"], function (mod1, mod2) {
// 使用模块
});
CMD(Common Module Definition)
CMD 是由 Sea.js 提出的另一种模块定义规范,它也支持异步加载模块,但相比 AMD 更加强调模块的就近依赖,即模块代码中可以立即使用依赖模块,而不需要等到依赖模块加载完成。
示例:
// 定义模块
define(function (require, exports, module) {
var dep1 = require("dependency1");
var dep2 = require("dependency2");
// 模块代码
});
// 加载模块
seajs.use(["module1", "module2"], function (mod1, mod2) {
// 使用模块
});
现在的使用实例
尽管 AMD 和 CMD 都是为了解决 JavaScript 模块化开发中的问题而提出的规范,但在实际应用中,AMD 更为流行和广泛使用,特别是在前端开发中。许多 JavaScript 库和框架如 RequireJS、Dojo Toolkit 等都采用了 AMD 规范。
一个现在仍在使用 AMD 规范的实例是使用 RequireJS 来管理前端模块。例如,在一个基于 RequireJS 的项目中,您可以定义和加载模块,实现模块化开发和异步加载依赖。
从输入 URL 到页面展示发生了什么
后端发生了什么
浅拷贝和深拷贝的区别
详情项目中的应用见之前写的[]
首先我们要明白,浅拷贝不等于赋值,赋值本质是对一个对象的引用,指向的地址是一样的,而浅拷贝是拷贝了一层源对象相同的引用,但是如果源对象的属性是引用类型的话,那么浅拷贝的对象的属性还是指向的源对象的属性,所以如果修改了浅拷贝的对象的属性的话,源对象的属性也会被修改
如果是基本的数据类型,你进行浅拷贝以后,就相当于新建了一个新的对象,但是如果是引用数据类型,像 Object,Array 等,那么浅拷贝的对象的属性还是指向的源对象的属性,所以如果修改了浅拷贝的对象的属性的话,源对象的属性也会被修改
浅拷贝
MDN 定义 对象的浅拷贝是其属性与拷贝源对象的属性共享相同引用(指向相同的底层值)的副本。因此,当你更改源或副本时,也可能导致其他对象也发生更改——也就是说,你可能会无意中对源或副本造成意料之外的更改。这种行为与深拷贝的行为形成对比,在深拷贝中,源和副本是完全独立的。
浅拷贝的方法
Object.assign
array.prototype.slice 直接修改原型链,copy 一个新的数组
array.prototype.
最简单的,解构赋值:
let obj =
深拷贝
深拷贝就相当于是完全创建了一个和源对象不同的副本,不会影响到源对象的属性
常见的深拷贝方法包括使用递归、JSON.parse(JSON.stringify(obj))、第三方库如 lodash 的_.cloneDeep()等。
// 深拷贝示例
const obj1 = { a: 1, b: { c: 2 } };
const obj2 = JSON.parse(JSON.stringify(obj1));
obj2.b.c = 3;
console.log(obj1); // { a: 1, b: { c: 2 } }
console.log(obj2); // { a: 1, b: { c: 3 } }